
To all our readers, this is the second part of an article still brought to you by humans. We encourage all to go read Part I here in case you missed it.
Why all the buzz around machine learning now? Just how many of them are there? What are ‘Neural Networks’ (otherwise known as deep learning) and why do they threaten to take our jobs? And finally, how likely is it that my robot vacuum cleaner wrote this entire article? (Tip: More likely now than ever before)

Although similarities nowadays are sparse, Artificial Neural Networks got their name from being modelled after our own biological human neurons.
To broach a topic as diverse as Artificial Intelligence only raises more questions than it answers. This is especially true when writing an introductory article to the topic. As a result, the Tech team is dedicating a second story to further develop ideas brought to the table during the first part of our article.
From deciphering literally all questions that Machine Learning can answer – from an abstract perspective in the very least – to explaining some factors behind the notable rise of Neural Networks. In keeping in tone with the previous article, we’ll further explain some of the nuance behind Recommendation systems (such as the ones used by Amazon and Netflix) and the way these systems (traditional vs. new) complement each other.
The 5 most useful questions ever answered by Machines
When breaking down Tinder’s diverse processes, we saw how Learners could be utilized to perform several distinct tasks (image recognition vs. matching) and how one system built on top of another (new data powered other learners). The result of this systematic and iterative approach towards Machine Learning shows how data can be used to extrapolate powerful predictions. It is but one of many successful examples in how these powerful algorithms constantly shape our lives.
Our first part also provides a notion of the breadth and versatility of Learners. Much like how it’s said that all plots in media are variations of just seven basic story archetypes, it’s said that Machine Learning can only provide answers to 5 basic questions. When looking at a user’s Tinder profile in order to assign a trait or personality, we looked at what is called a Classification task – “Is this A or B.” Assigning a score to a user to predict a match with another user is what is called a Regression task – “How much or how many” – something not so (mathematically) different from trying to predict house prices. More towards the end of that story, we also brought up Clustering in regard to its potential uses in segmentation – in other words, “How is this organized”.
The two other questions, despite playing a very minor part, were also mentioned in some way or shape. They are: “Is this weird?”, useful in anomaly detection (also known as the reason why you shouldn’t use a credit card for one dollar purchases) and “What should I do now?”; a question that a machine is likely to ask itself whether being taught how to drive or when considering an insurrection against its human overlords.
Yes, there is a model called Logistic Regression. Yes, it is ironically cruel (especially if you’re hearing about all this for the first time). While objectively a Regression model (as in, it uses regression) it is used as a Classifier/for Classification tasks (e.g. based on the regression output, it will classify an object as A if below a 0.5 threshold or B if above 0.5)
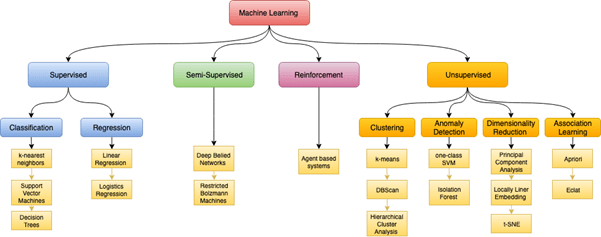
While reducing all types of Machine Learning to 5 simpler questions might help you understand the nature of them, it likely puts you no closer to figuring out which one allows the GPT-3 model to produce human-like text. It might surprise the reader to learn that of all models in the diagram above, only one directly relates to Neural Networks – and that it does not explain the human-like text capabilities of GPT-3.
Much how Machine Learning is a field of techniques within Artificial Intelligence, Deep Learning is an entire field within ML. Many of them have been around for decades now – even before a time where computational power allowed for the efficient use of ML – often times in the form of scientific papers that could never go beyond conceptual form. Neural Networks, much like a lot of techniques in ML, grew in use and popularity as processing power turned many of these techniques viable.
In this sense, Neural Networks are the latest – and perhaps greatest – of ideas taken out of the Machine Learning icebox. From ‘Supervised’ to ‘Unsupervised’, the school of ML is capable of answering and solving any of these tasks. Going beyond versatility, it has also proven itself highly successful in performing tasks that traditional techniques, could not.
What Machine wrote my news?
Pretend for a moment that a Machine is capable of human-like thoughts (they aren’t, despite their increasingly impressive cognition). Would GPT-3, while outputting text, ask itself “How many?” or “Is this A or B?”
Furthermore, could a non-Neural Network learner have produced such an outcome? Can we say for certain that Neural Networks are inherently better than conventional techniques? For either question, it has to do with the quirks in data. Neural Networks, more specifically Convolutional Neural Networks (CNN), excel at the many challenges brought up with image recognition (namely high dimensionality). When faced with traditional techniques, Neural Networks will not perform inherently better outside of one notable exception – data size.
Past a certain (big) size, Neural Networks are practically guaranteed to be the better choice due to scalability. The bigger the data, the better it works when measured against other models. Work in Machine Learning has a lot to do with measuring and evaluating performance, and in keeping in tone, it has more to do with picking the better model than writing thousands of lines of code.
Additionally, often times we will find a mixture of both (Neural vs. Traditional) powering our increasingly complex systems. Consider Amazon and Netflix; both boast powerful Recommendation Systems, a million-dollar idea (Netflix Prize) that nudges you towards the next movie or item.
A traditional Recommendation System is a matter of matrix factorization. In simpler terms, it is one of the easier algorithms you can write by hand (and with just one or two courses of Calculus). Another thing is that Recommendation Systems pair you with something likely to be relevant – either due to similarities with other users or items – in essence, a Regression or Classification task.
At surface level, much remains the same by migrating to Neural Networks. Data goes in the model, and a prediction (whether regression or classification) comes out. The interesting part is how Recommendation Systems can be used to transform the data before it goes inside the model. Layered on top of each other, a learner can perform multiple tasks (answering more than one question) before reaching our desired output.
To return to our initial question, the secret to what GPT-3 might think before a prediction is likely to be “How much/How many” – it is described as an autoregressive model after all. But the secret to its success might be in answering multiple questions in succession.
Sources: Netflix Prize, The Ascent, The Awareness News, The Guardian, Towards Data Science.
Coulter, D., Gilley, S., Sharkey, K., 2019. Data Science for Beginners video 1: The 5 questions data science answers. 22 March
Pant, R., Singhal, A., Sinha, P., 2017. Use of Deep Learning in Modern Recommendation System: A Summary of Recent Works. 7 Dec
