
“Machine Learning is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it…”
Machine Learning (ML) and Artificial Intelligence (AI) are buzzwords often used interchangeably in the casual and intellectual discourse of today. Many ideas often spring to mind when either is mentioned: data science, self-driving technology, big data and, on the more ridiculous side, robots hellbent on humanity’s destruction. The truth, however, is that Machine Learning is part of our increasingly data-driven world. It makes our lives better, despite several shortcomings, and is likely to be relevant to you even when not working directly with it.
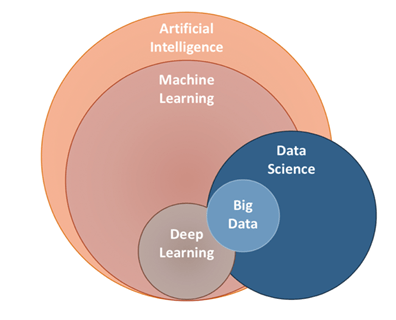
Let us take a quick moment to make the distinction between ML and AI. Consider the picture above: Machine Learning, a subset of AI, is a field dedicated to generating predictions based on the hidden patterns, machines pick up within data. In practice, it is an AI technique where the machine writes its own rules. This means that a machine is fed with inputs (in tabular form) such as housing data or photos of dogs and cats, and it learns to perform a specific task without humans telling it how to do so.
In this article, we hope to explore some interesting case studies, such as how Tinder uses these learners to match you with your next date or how Amazon attempted to use an algorithm to analyse CVs (revealing a bias against women instead). With Tinder, for example, a machine takes our explicit (e.g. age range) and implicit (e.g. our photo was taken in a forest) preferences to match us with people likely to be a match. This is a task performed by several algorithms (or learners/machines), each one trained specifically for its task.
How does my swiping allow a Machine to learn?
Tinder uses an ELO-system, attributing a score to every user. Based on this score it will determine the likelihood of two individuals swiping right on each other, resulting in a match. This score is determined by multiple factors, such as the photos, bio and other settings of the profile, as well as swiping activity. Users with similar ELO scores, who have been identified as sharing similar interests, will be shown to each other.
Let us refer to the diagram below.
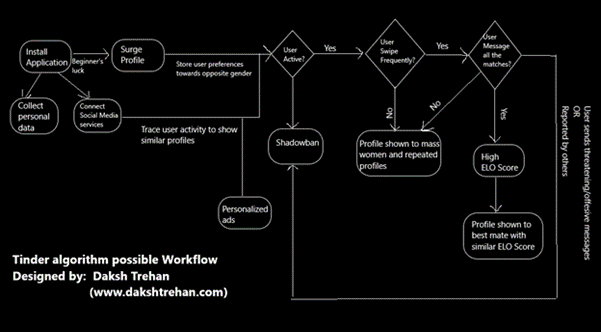
Firstly, the algorithm starts by analysing the user’s profile and collecting information from the photos they posted and personal information they wrote on their bio. In the photos, the algorithm can pick up on interests or cues such as liking dogs or nature. Through the bio, the machine will profile you based on words and expressions used (see picture below). From a technical perspective, these are distinct tasks likely to be performed by different learners – identifying words and sentiments is fundamentally different recognizing dogs in pictures.

At this point, Tinder does still not have much knowledge about one’s preferences and will therefore show your profile to other users at random. It will record the swiping activity and the characteristics of the persons swiping right or left. Additionally, it will identify more features or interests from the user and attempt to present the profile to others in a way that it will increase the likelihood of someone swiping right. As it collects more data, it becomes better at matching you.
The ‘Smart Photos’ option, a feature that places your ‘best’ or ‘most popular’ photo first, is also another instance where Tinder uses Machine Learning. Through a random process in which a profile and pictures are shown to different people in different orders, it will eventually create a ranking for your photos.
In Smart Photos, the main goal is for you to be matched. This works best when the most relevant picture is placed first. This could mean that the most ‘popular’ photo – the one that performed better – might not be the best; think of someone who likes animals. For these people, the photo of you holding a dog is likely to be shown first! Through the work of creating and ranking preferences and choices, a match can be found solely on the valuable insights from a photo.
By and large, the techniques that match you with other people as described above are part of a school of techniques in Machine Learning called ‘Supervised Learning’. In other words, the algorithm that learns to identify dogs and nature has been trained with similar pictures of dogs and nature. These stand in contrast with other schools, such as ‘Semi-supervised Learning’ and ‘Unsupervised Learning’.
The Perils of our (Human) Supervisors
In 2014, a group of Amazon engineers were tasked with developing a learner that could help the company filter the best candidates out of the thousands of applications. The algorithm would be given data with past applicants’ CVs, as well as the knowledge of whether said applicants were hired by their human evaluators – a supervised learning task. Considering the tens of thousands of CVs that Amazon receives, automating this process could save thousands of hours.
The resulting learner, however, had one major flaw: it was biased against women, a trait it picked up from the predominantly male decision-makers responsible for hiring. It started penalizing CVs where mentions of the female gender were present, as would be the case in a CV where “Women’s chess club” was written.
To make matters worse, when the engineers adjusted so that the learner would ignore explicit mentions to gender, it started picking up on the implicit references. It detected non-gendered words that were more likely to be used by women. These challenges, plus the negative press, would see the project be abandoned.
Problems such as these, arising from imperfect data, are linked to an increasingly important concept in Machine Learning called Data Auditing. If Amazon wanted to produce a Learner that was unbiased against women, a dataset with a balanced amount of female CV’s, as well as unbiased hiring decisions, would have to have been used.
The Unsupervised Techniques of Machine Learning
The focus up until now has been supervised ML types. But what of the other types are there?
In Unsupervised Learning, algorithms are given a degree of freedom that the Tinder and Amazon ones do not have: the unsupervised algorithms are only given the inputs, i.e. the dataset, and not the outputs (or a desired result). These divide themselves into two main techniques: Clustering and Dimensionality Reduction.
Remember when in kindergarten you had to identify different shades of red or green into their respective colour? Clustering works in a similar way: by exploring and analysing the features of each datapoint, the algorithm finds different subgroups to structure the data. The number of groups is a task that that can be made either by the person behind the algorithm or the machine itself. If left alone, it will start at a random number, and reiterate until it finds an optimal number of clusters (groups) to interpret the data accurately based on the variance.

There are many real-world applications for this technique. Think about marketing research for a second: when a large company wants to group its customers for marketing purposes, they start by segmentation; grouping customers into similar groups. Clustering is the perfect technique for such a task; not only is it more likely to do a better job than a human – detecting hidden patterns likely to go unnoticed by us – but also revealing new insights regarding their customers. Even fields as distinct as biology and astronomy have great use for this technique, making it a powerful tool!
Ultimately brief, Machine Learning is a vast and profound topic with many implications for us in real life. If you’re interested in learning more about this topic, be sure to check out the second part of this article!
Sources: Geeks for Geeks, Medium, Reuters, The App Solutions, Towards Data Science.
 Daniel André
Daniel André  Laura Osório
Laura Osório André Rodrigues
André Rodrigues